Hadoop培训课程:Hadoop简单介绍
最新学讯:近期OCP认证正在报名中,因考试人员较多请尽快报名获取最近考试时间,报名费用请联系在线老师,甲骨文官方认证,报名从速!
我要咨询Hadoop简介
Apache Hadoop软件库是一个框架,允许在集群服务器上使用简单的编程模型对大数据集进行分布式处理。Hadoop被设计成能够从单台服务器扩展到数以千计的服务器,每台服务器都有本地的计算和存储资源。Hadoop的高可用性并不依赖硬件,其代码库自身就能在应用层侦测并处理硬件故障,因此能基于服务器集群提供高可用性的服务。
1.2Hadoop生态系统
经过多年的发展形成了Hadoop1.X生态系统,其结构如下图所示:
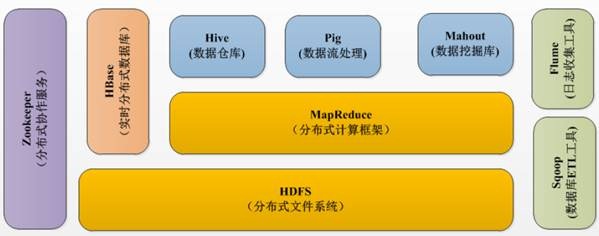
lHDFS--Hadoop生态圈的基本组成部分是Hadoop分布式文件系统(HDFS)。HDFS是一种数据分布式保存机制,数据被保存在计算机集群上,HDFS为HBase等工具提供了基础。
lMapReduce--Hadoop的主要执行框架是MapReduce,它是一个分布式、并行处理的编程模型,MapReduce把任务分为map(映射)阶段和reduce(化简)。由于MapReduce工作原理的特性, Hadoop能以并行的方式访问数据,从而实现快速访问数据。
lHbase--HBase是一个建立在HDFS之上,面向列的NoSQL数据库,用于快速读/写大量数据。HBase使用Zookeeper进行管理,确保所有组件都正常运行。
lZookeeper--用于Hadoop的分布式协调服务。Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
lPig--它是MapReduce编程的复杂性的抽象。Pig平台包括运行环境和用于分析Hadoop数据集的脚本语言(Pig Latin)。其编译器将Pig Latin翻译成MapReduce程序序列。
lHive--Hive类似于SQL高级语言,用于运行存储在Hadoop上的查询语句,Hive让不熟悉MapReduce开发人员也能编写数据查询语句,然后这些语句被翻译为Hadoop上面的MapReduce任务。像Pig一样,Hive作为一个抽象层工具,吸引了很多熟悉SQL而不是Java编程的数据分析师。
lSqoop是一个连接工具,用于在关系数据库、数据仓库和Hadoop之间转移数据。Sqoop利用数据库技术描述架构,进行数据的导入/导出;利用MapReduce实现并行化运行和容错技术。
lFlume提供了分布式、可靠、高效的服务,用于收集、汇总大数据,并将单台计算机的大量数据转移到HDFS。它基于一个简单而灵活的架构,并提供了数据流的流。它利用简单的可扩展的数据模型,将企业中多台计算机上的数据转移到Hadoop
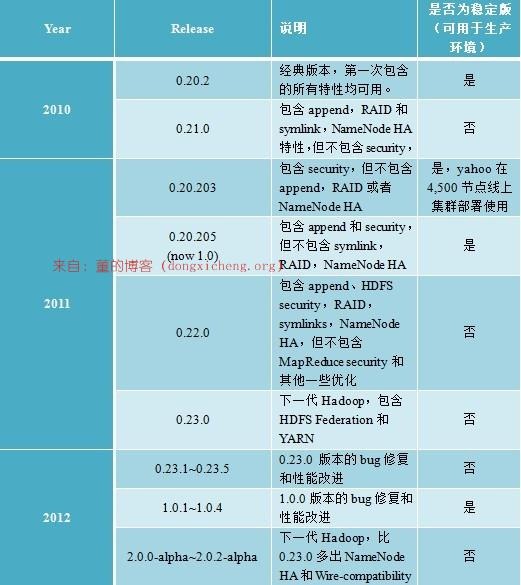
1.3Apache版本衍化
Apache Hadoop版本分为两代,我们将第一代Hadoop称为Hadoop 1.0,第二代Hadoop称为Hadoop 2.0。第一代Hadoop包含三个大版本,分别是0.20.x,0.21.x和0.22.x,其中,0.20.x最后演化成1.0.x,变成了稳定版,而0.21.x和0.22.x包含NameNode HA等新的重大特性。第二代Hadoop包含两个版本,分别是0.23.x和2.x,它们完全不同于Hadoop 1.0,是一套全新的架构,均包含HDFS Federation和YARN两个系统,相比于0.23.x,2.x增加了NameNode HA和Wire-compatibility两个重大特性。